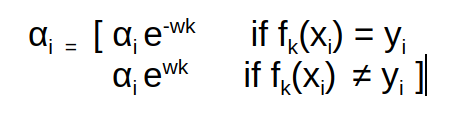Interview Questions and Answers of Machine Learning
Have a new project in mind? Need help with an ongoing one? Drop us a line about your project needs, we answer same day.
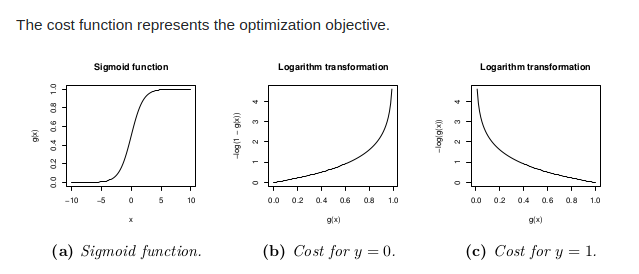
Q1. Why cost function used for linear regression cannot be used for logistic regression?
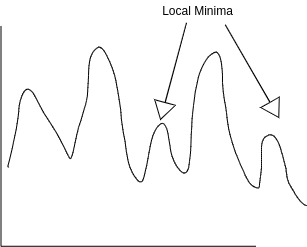
Mean Squared Error(Cost function) which is used for linear regression will be a very ziggly plot(non-convex function) for sigmoid function(for cost function) used in logistic regression. It will not be able to converge and stuck in local minimas.
Q2. Why cost function of logistic regression has log term?
Simple sigmoid function will be a non-convex function so while taking derivative it will be a ziggly plot. Hence, higher chances of stucking into local minima before reaching global minimum.
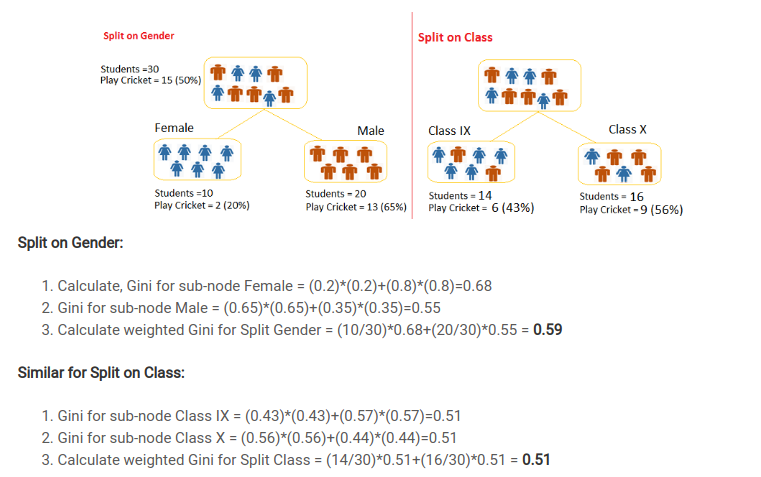
Q3. What is gini index and how is it used in decision trees?
In layman terms, Gini index is a statistical dispersion which measures the inequality or uncertainity in a block. In terms of decision tree, It will check the purity/homogenity of a node which helps in splitting on that node. Higher the gini index, higher the homogenity. Below diagram shows how to calculate gini index
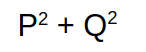
Here p: success and q:failure
References -> Analytics Vidhya
Q4. What is Information Gain and Entropy?
Entropy is a measure of the uncertainity associated with a set of probabilities. Information gain and entropy is inversely related. If higher entropy then low information gain is required i.e, node is pure.
Q5. How to choose no. of trees in Random Forest?
Generally, higher the no. of trees is good but a practice is to limit till 200 or 300(depends on # datapoints as well). As you will increase the no. of trees, it will take more time and there is a chance of incease in biasness because for no. of samples(randomly selected) for a tree is the possibility of repition.
Q6. How to choose weights for trees in random forest?
In random forest, each tree is equally weighted as they are trained on p random features.This ensures that each tree is grown such that -:
1. Reduce Variance - Does not overfit the training data
2. Reduce biasness- Generalise better to new data
Q7. Why exponential function(e) is used in recomputing the weights of data points in Adaboost algorithm?
It decreases the weights if data point is correctly classified and vice-versa.
Explanation with formula. Suppose ai are weights for data points